Databases Are Not Becoming Chatbots

Over the last months, while building Tabularis, I started realizing that I was not just building a database client.
I was running into a bigger question: what happens to databases when software no longer just reads and writes records, but also tries to interpret schema, suggest queries, explain execution plans, preserve working context, and collaborate with language models?
I do not have a final answer, but I am starting to form a position.
My current view is that the natural evolution of databases is not that they become chatbots. I also do not think they become "AI-native" in the vague marketing sense that phrase usually carries.
What is changing is the layer around the database.
Databases still matter because structured truth still matters. Tables, constraints, indexes, transactions, and schemas are not becoming obsolete just because language models are good at generating plausible text. If anything, they become more important when the surrounding software becomes probabilistic.
What AI changes is not the need for a system of record. It changes the system of interpretation, navigation, and action around that record.
That shift is becoming very concrete to me in Tabularis.
Once you put a SQL editor, AI-assisted query generation, query explanation, visual explain plans, notebooks, MCP integration, and a plugin system in the same product, the old idea of a database client starts to feel incomplete.
A database client used to be a place where you connected to a server, browsed tables, wrote some SQL, inspected results, and moved on. That model is still useful, but it no longer feels sufficient.
The moment AI enters the workflow, the client becomes something else: a coordination layer between a human trying to understand a system, a database holding structured truth, and a model trying to compress, interpret, and act on context.
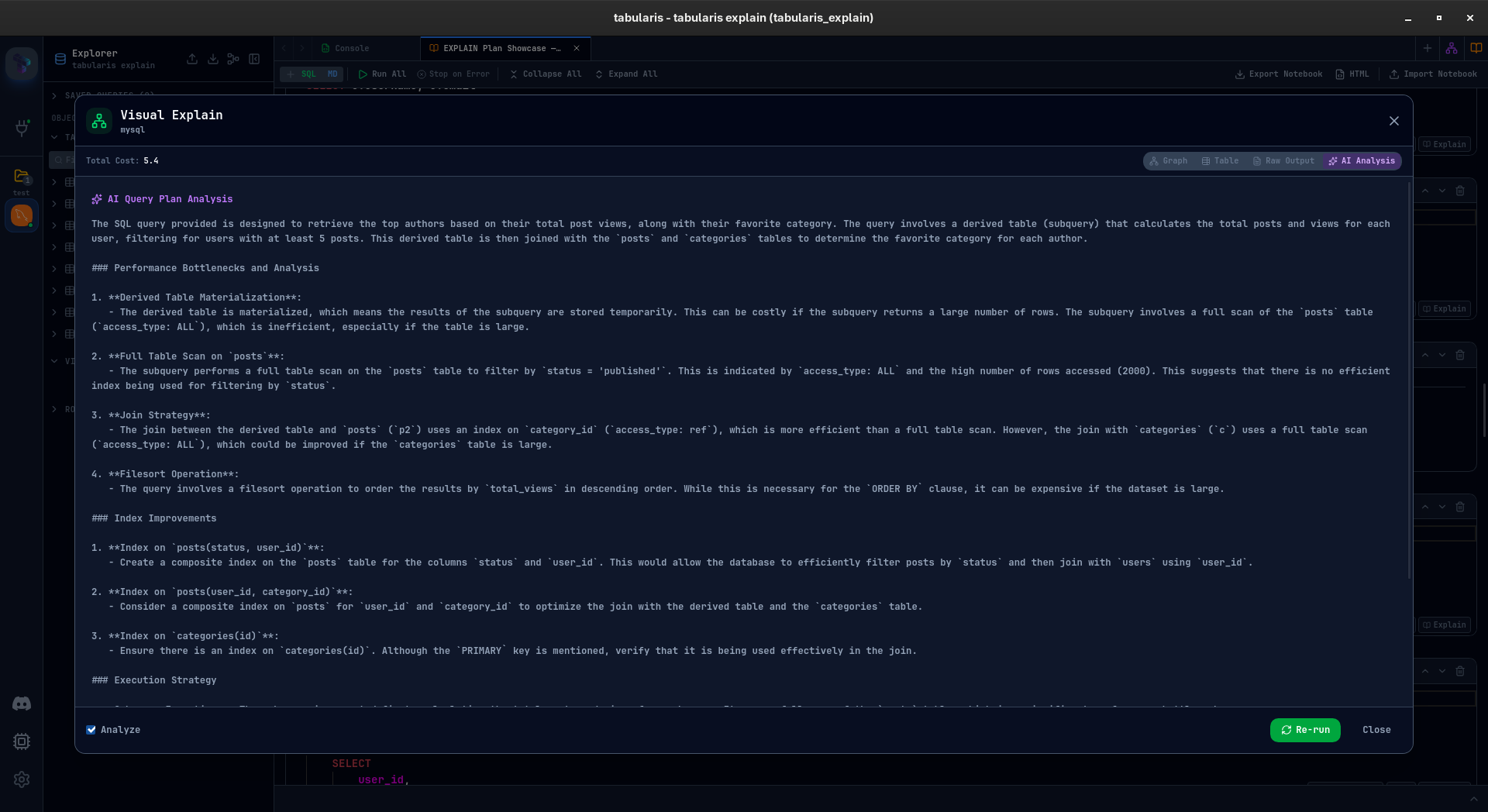
One of the signals for me: the useful part is not just generating SQL, but helping make reasoning around queries and plans more legible.
The Part I Keep Coming Back To
The strongest idea I keep circling back to is this: the real change is not that databases start speaking natural language. The real change is that the workflow around data becomes more contextual, more stateful, and more collaborative.
In Tabularis, that is visible in small ways and large ones.
An AI overlay in the editor is not just a shortcut for writing SQL faster. Query explanation is not just a convenience feature for beginners. Visual EXPLAIN is not just a prettier way to look at query plans. Notebooks are not just a nicer place to collect queries. MCP is not just another integration checkbox.
Taken together, they point in the same direction. Database work is moving away from isolated commands and toward systems that help users build, inspect, preserve, and reuse context.
That is the part that feels important to me.
The Technical Decisions I Am Making in Tabularis
Building Tabularis has forced me to make a few technical bets. They are still bets, not conclusions, but they say a lot about what I currently believe.
1. AI should not become the source of truth
This is the most important one.
I do not want AI to replace schema, queries, plans, or results. I want it to sit above them as a layer of interpretation.
That sounds obvious, but it is easy to blur this boundary. A generated query can start feeling authoritative. A natural-language explanation can sound more reliable than the actual execution plan. A confident answer can quietly push the user into trusting the model more than the database.
I do not think that is a healthy direction.
In Tabularis, the database should remain the thing that is real. The AI layer should help the user access, understand, and manipulate that reality, but it should not quietly replace it.
2. AI should stay optional
I am keeping AI optional in Tabularis, and that choice is partly practical but also philosophical.
I do not think the future of database tooling should collapse into a single provider, a single model family, or even a single interaction style. Some users want OpenAI-compatible APIs. Some want Anthropic. Some want Ollama. Some want no AI at all.
I do not think that flexibility is just a commercial checkbox. I think it reflects the right abstraction. The stable thing is not the model. The stable thing is the workflow.
3. Preserved context matters more than one-shot generation
This is probably the bet that has become stronger as I kept building.
A lot of AI product design still assumes that the main value is in producing an answer quickly. Sometimes that is true. But in database work, I suspect a large part of the value is not generation but preserved context.
Why did I run this query?
What assumption was I testing?
What did the previous result suggest?
Which part of the schema turned out to matter?
Why does this plan get expensive at this join?
That is why notebooks and explainability feel so important to me in Tabularis.
A notebook is not just a better place to put SQL and Markdown. It is a form of working memory. Visual explainability is not just an educational feature. It is a way to make optimization reasoning legible.
The more I work on the product, the more I think memory and explanation are more durable primitives than raw generation.
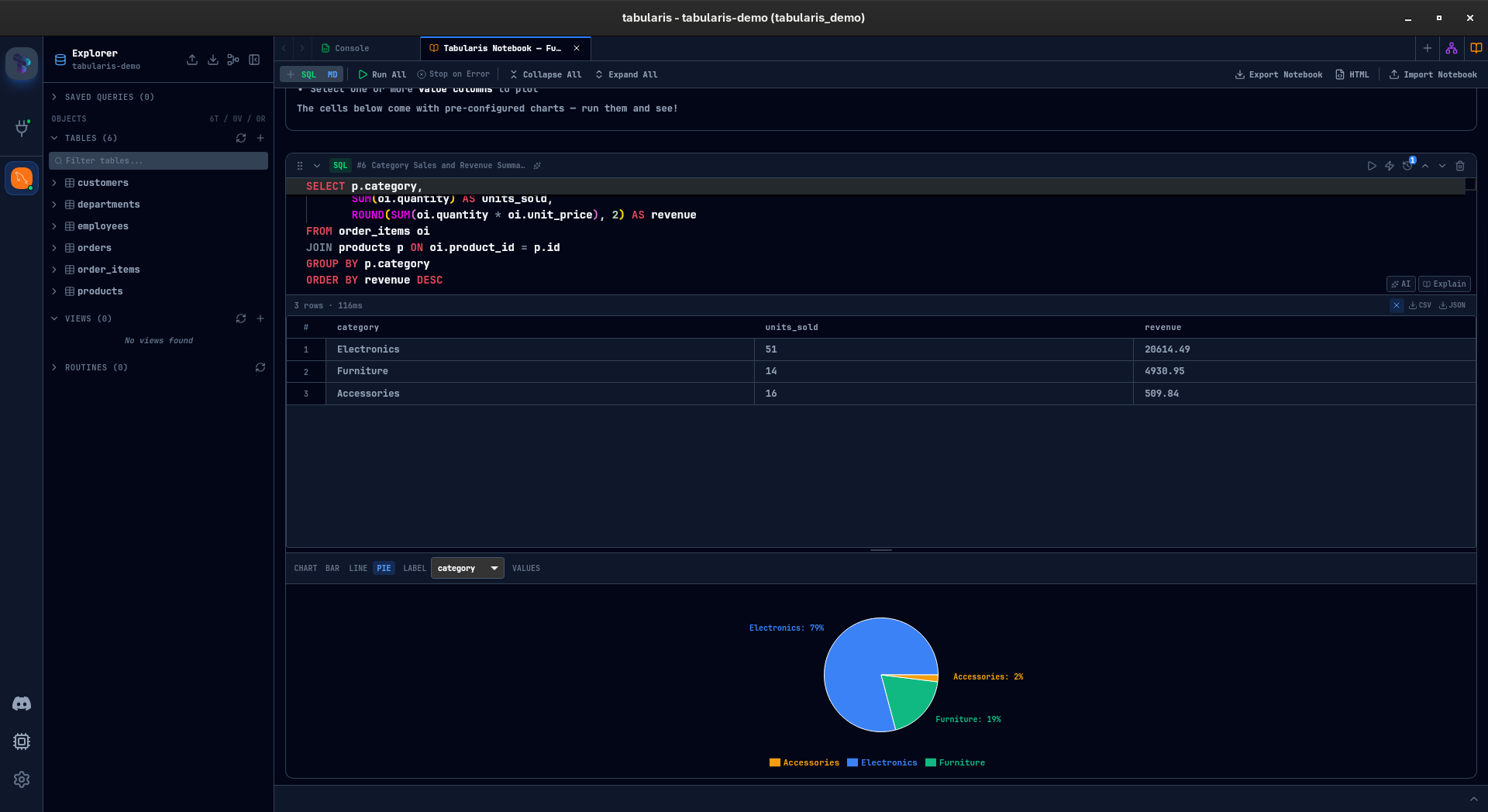
The more I work on notebooks, the more I think preserved context is a deeper primitive than one-shot AI output.
4. The future probably looks more composable than monolithic
I am also leaning into MCP and plugins because I increasingly doubt that the future here will be monolithic.
I do not think there will be one magical "AI database" that cleanly absorbs querying, reasoning, context management, automation, and verification into a single perfect layer.
I think the more likely future is composable.
Databases will remain databases. Models will remain models. Clients, agents, plugins, and protocols will mediate between them.
Tabularis keeps pushing me toward that conclusion because the moment you try to support real workflows, you discover that no single surface is enough.
The Mistakes I Think I May Be Making
This is the part I trust the most, because it is the least polished.
I am not just making decisions. I am also building under uncertainty, and some of that uncertainty is probably pointing at mistakes.
I may be using AI where better UX would solve the problem more cleanly
There is always a temptation to add a generative layer when the actual problem is discoverability, information architecture, or interface design.
If a user cannot find the right table, understand a relationship, or inspect a plan easily, an AI-generated explanation may help. But it may also hide the fact that the product itself is not yet clear enough.
I think this is one of the easiest traps to fall into. AI can compensate for weak product decisions just well enough to make those decisions look acceptable.
I may be overestimating how often users want generation instead of control
It is easy, especially when building AI features, to assume that the more the system does for the user, the better.
I am not convinced that is true in database tooling.
A lot of serious database work is not blocked by typing speed. It is blocked by ambiguity, risk, context switching, and lack of confidence.
In that world, the winning feature may not be "generate the query for me." It may be "help me trust what I am about to run."
Those are very different product instincts.
I may be underestimating reproducibility and auditability
A query written by a human is imperfect, but it is usually inspectable in a straightforward way.
A suggestion generated from a changing prompt, dynamic schema context, model-specific behavior, and hidden retrieval steps is much harder to reason about after the fact.
If AI becomes part of database work, then being able to understand why something was suggested, what context was used, and how a decision was derived becomes much more important.
I suspect the industry still talks too much about generation quality and too little about decision traceability.
I may be designing too much for the future
This is the most uncomfortable possibility.
Once you start seeing where things might go, it becomes tempting to over-architect for a world that has not arrived yet.
Maybe some of what I think will become core will remain peripheral. Maybe the average user does not want an AI-mediated database environment. Maybe they just want a fast editor, a clear schema browser, and fewer rough edges.
I try to keep that possibility in mind because future-facing product conviction can become self-indulgent very quickly.
Finding Tabularis useful? Star it on GitHub — it takes a second and helps more developers discover the project. Star on GitHubWhat I Think Is Actually Emerging
I do not think databases are going away.
I do not think SQL is going away.
I do not think language models replace the need for carefully modeled data, explicit constraints, or systems that can be trusted.
But I do think the center of gravity is shifting.
More of the value around data work will sit in context management, interpretation, explainability, derivation, memory of prior work, and tool-mediated action around the database itself.
That does not make the database less important. If anything, it makes it more important, because the rest of the system becomes softer and less deterministic.
The database remains the anchor.
What changes is everything around it.
Tabularis, at least for me, is a way to explore that shift in concrete form.
Not as a grand theory, and definitely not as a finished answer, but as a product that keeps forcing the question.
Every time I add AI to query writing, explanation to plans, notebooks to analysis, or MCP to agent workflows, I feel the same tension: the old boundaries between client, assistant, and interface to the database are getting weaker.
I may be wrong about where that leads.
I may be making some of the wrong bets too early.
But I am increasingly convinced that the old model of "database client as editor plus grid plus manual querying" is no longer enough.
Something wider is emerging around the database, and building Tabularis is my way of trying to understand what it is.